
AIの活用を考えると、まず最初に思い浮かぶのが画像認識モデルを使って何かする・・・ということです。弊社でも協業で口腔画像や、不動産の物件写真の認識モデルを作成し、それを活用するアプリも作るといったお仕事に携わっています。
その際、どうやって画像認識モデルを作るかというと、手っ取り早いのはWatson Visual Recognitionのような画像認識APIサービスを使うという方法です。そうしたサービスで充分な精度が得られない場合は、TensorFlowを用いて完全に独自のモデルを開発することもあります。
最近、MicrosoftがLobeというツールを発表しました。Lobe.aiというサイトで公開されており、少なくとも現時点では無料で使用することができます。
モデルの作成は簡単
Lobeはクラウドサービスではなく、Windows PCかMacで動作するソフトウェアで、LobeのWebサイトからダウンロードして自分のPCにインストールして使います。
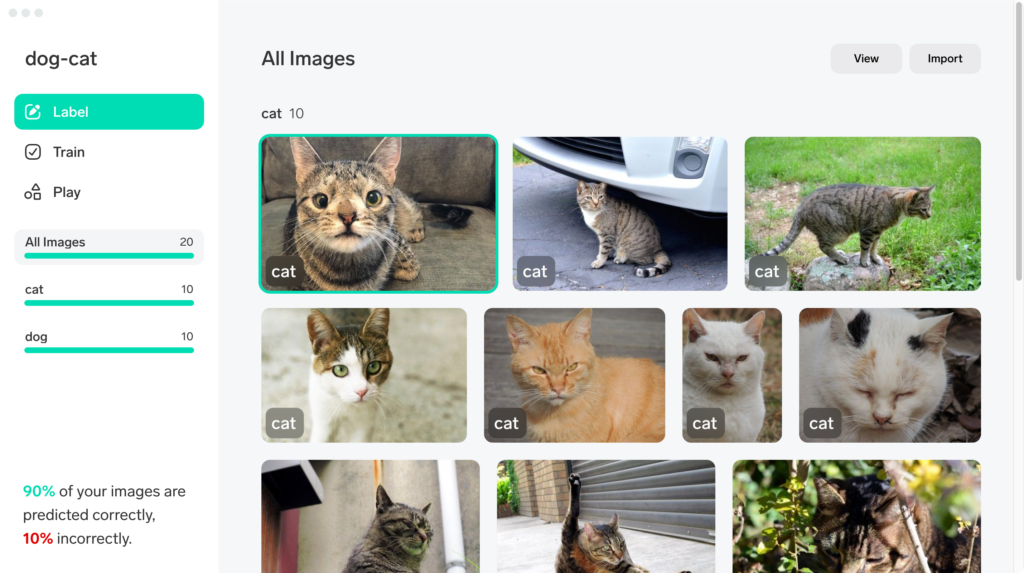
操作は非常に簡単で、分類を行いたい画像、例えば犬と猫ならそれぞれの画像を準備して、Lobeにドラッグアンドドロップし、それぞれの画像にdogやcatといったラベルを付けていけば、どんどんモデルの学習が進みます。上図では犬の画像を10枚、猫の画像を10枚準備したのですが、90%の精度で正しく分類できるモデルが作成されています。さらに精度を上げたければ、基本的には画像を増やしていきます。
作ったモデルの活用も万全
モデルを簡単に作成できても、活用ができないのであれば、ただのお遊びというか、単なるデモに過ぎません。
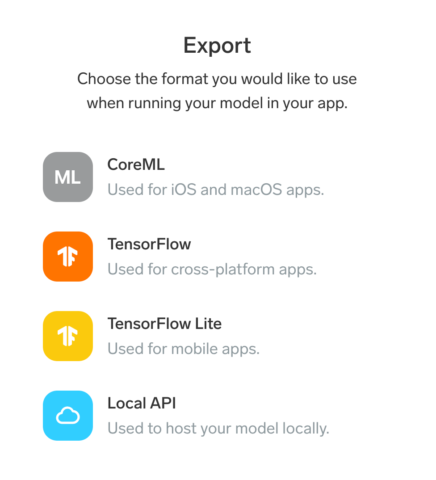
Lobeが凄いのは、作ったモデルの活用法がちゃんと考えられていることです。モデルを作成した後に、Exportメニューを開くと、上図のような画面が表示されます。AppleのiOSデバイス(iPhoneやiPad)またはMacで使用できるCoreMLというApple純正の機械学習ライブラリ用にモデルをエクスポートできるほか、ディープラーニングのデファクトスタンダードであるTensorFlowや、Raspberry Piのようなデバイスでも使用できるTensorFlow Liteの形式にすることも可能。さらに、適当なPCをサーバにしてLocal APIを作るという方法も採れます。
AIの活用では、まずモデルを作り(学習フェーズ)、そのモデルを使う(推論フェーズ)という工程が必要ですが、学習フェーズについてはLobeを使って中小企業などでも自分たちの手で行い、推論フェーズは少し技術力が必要になるので、プロに任せてアプリを作る(既存システムに組み込む)といったことが可能になるわけです。
すべてローカルで動作する(クラウド不要)
ここまでの説明でも何となく予想されることかと思いますが、Lobeの動作にはクラウドは不要です。ローカルのPC、Macがあれば、それでOKです。クラウドを使わないということは、学習のために多少マシンパワーが必要ということになりますが、課金が発生する可能性が将来的にも極めて低い(現状のLobeはBeta版扱いですが、使用期限があるように見えない)ということでもあります。
PCへのインストールが必要にはなりますが、何らかのクラウドサービスにユーザ登録を行うということがないので、教育で使うのもありかもしれません。
作成できるのは分類モデルのみ
画像認識モデルには、下記の3種類があります。
- 画像分類(単純に画像を分類する。何が写っているか?である必要はない)
- 画像検出(画像のどこに何が写っているかを認識する)
- 画像セグメンテーション(画像の各ピクセルの意味を分類する)
Lobeで作成できるのは最も単純な画像分類だけです。あくまで画像を分類するだけなので、先ほどの例のように「犬が写っている」とか「猫が写っている」のような被写体での分類にこだわる必要はなく、「良い写真」、「悪い写真」というような分類でも構いません。
画像のどこに何が写っているというような画像検出が必要な場合は、現時点ではLobeは使えません。
画像認識モデル作成の敷居を一気に下げた
Lobeは画像分類についてはこれ以上ないというほどモデル作成の敷居を下げました。Microsoftは第3次AIブームが始まった当初から「AIの民主化」を意識した研究開発を行っていますが、Lobeはその最たるものといえるのではないでしょうか。