エッジAIに関する調査の続きということで、TensorFlow Liteを試してみました。

エッジデバイスは基本的に計算性能が貧弱なので、別の環境で作成した学習済みモデルを軽量化し、推論のみをエッジ側で行うというソリューションです。TensorFlowで作成したモデルをLite用に変換するという方法を取ります。
TensorFlowモデルを作るのはなかなかかったるい(TensorFlow 2.0だとそうでもないみたいですが)ので、いつもどおりKerasでモデルを作って、それをTensorFlow Lite用に変換していきます。
KerasでCNNモデルの作成
まず、データセットの準備。いつもどおりのMNISTです。
from keras.datasets import mnist
from keras.utils import to_categorical
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# shape[0]はデータの個数、(28, 28)を(28, 28, 1)に
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1)
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1)
# データの正規化
X_train = X_train / 255
X_test = X_test / 255
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
次にKerasでCNNモデルを作ります。極めて単純なモデル。
from keras.models import Sequential
from keras.layers import Dense, Activation, Conv2D, MaxPooling2D, Flatten
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), padding='same', input_shape=(28, 28, 1)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dense(10))
model.add(Activation('softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
学習します。今回は簡単にするためエポックは5。MacBook Proだと1分半くらいで学習が終わります。
# 学習
model.fit(X_train, y_train, batch_size=32, epochs=5, verbose=1)
# 評価
loss, accuracy = model.evaluate(X_test, y_test, verbose=0)
print('Accuracy', '{:.2f}'.format(accuracy))
で、ここで作成したKerasモデルをh5ファイルに保存します。
model.save('mnist.h5')
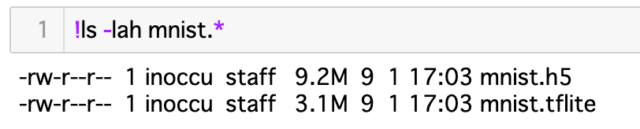
ファイルサイズを見てみると、9.2MBあります。

TensorFlow Liteモデルに変換
モデルの変換もPythonでできます。
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_keras_model_file("mnist.h5")
tflite_model = converter.convert()
open("mnist.tflite", "wb").write(tflite_model)
ファイルサイズを比べてみると、だいたい3分の1になっていることが分かります。
TensorFlow Liteモデルで推論
次に推論処理を行います。これはRaspberry Piあたりでやりたいところですが、ひとまずMacBook Pro上でやってしまいます。(Raspberry Piでの推論はまた今度)
import numpy as np
import tensorflow as tf
interpreter = tf.lite.Interpreter(model_path="mnist.tflite")
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
allocate_tensors()はメモリの確保で、モデルの読み込み直後に必須らしい。
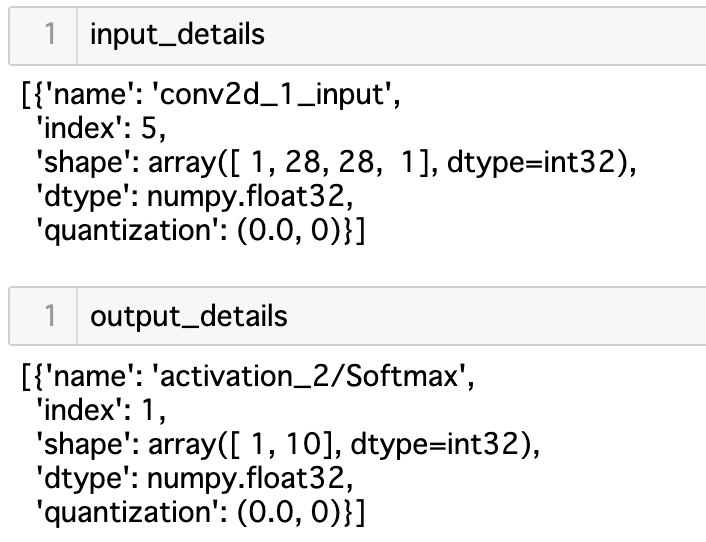
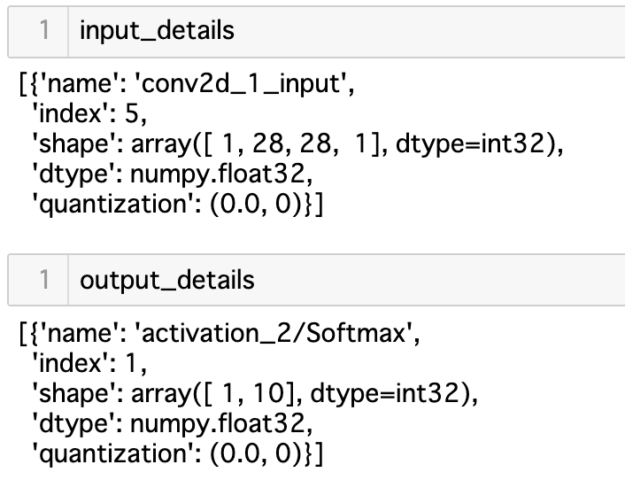
get_input_details()とget_output_details()は、入力と出力の形状を示すもので、このあと使います。ちなみにこんな出力。
いざ推論です。
input_shape = input_details[0]['shape']
input_data = np.reshape(X_test[0], input_shape)
interpreter.set_tensor(input_details[0]['index'], np.array(input_data, dtype=np.float32))
interpreter.invoke()
output_data = interpreter.get_tensor(output_details[0]['index'])
print(output_data)
出力結果は、このとおり。
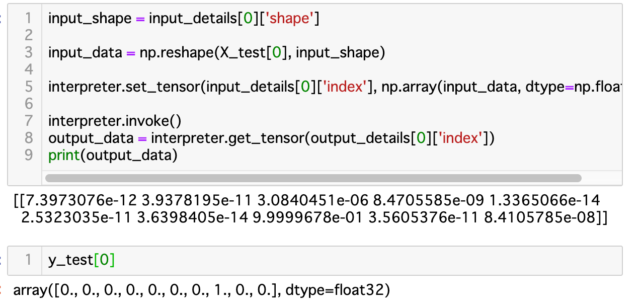
y_test[0]で正答が7であることが分かりますが、推論の結果を見てみると、ちょうど7にあたるところが9.9999678e-01になっています。よーよーご名答!
ということで、実際のエッジデバイスでの検証は次の機会に。