先日書いたこちらの記事で、いくつかのクラウドサービスにTensorFlowモデルをデプロイすることを試してみるということを書きました。


手始めにAWSからやってみようと思って、SageMakerのドキュメントを読んでいたのですが、SageMakerのNotebookで作ったモデルについては、比較的簡単にデプロイできそうなものの、あらかじめ作成済のモデルをデプロイするには、DockerでTensorFlow Servingを動かすようにして、それをSageMakerでホストするということらしい。なかなか、面倒そうだ…。
ということで、ひとまずSageMakerは関係なしに、手元のDocker環境でTensorFlow Servingを動かしてみようと思います。それをきちんとやっておけば、次にSageMakerで試す時に理解が早いだろうし。
Irisデータセットでモデルを作る
まずはデプロイするモデルを作らなければなりません。ここは手短にIrisデータセットで適当なモデルを作り、トレーニングします。
from sklearn import datasets
from sklearn import preprocessing
from keras.utils import np_utils
from sklearn.model_selection import train_test_split
from keras.models import Sequential
from keras.layers.core import Dense, Activation
iris = datasets.load_iris()
X = iris.data
y = iris.target
X = preprocessing.scale(X)
y = np_utils.to_categorical(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
model = Sequential()
model.add(Dense(16, input_shape=(4,)))
model.add(Activation('relu'))
model.add(Dense(3))
model.add(Activation('softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=50, batch_size=1, verbose=1)
トレーニングが終わったら、モデルを保存します。
model.save('iris-20200719.h5')
SavedModel形式に変換
保存したモデル(h5形式)を、TensorFlow Servingで動作させるためにSavedModel形式に変換します。
import tensorflow as tf
import keras
from tensorflow.python.estimator.export import export
estimator = tf.keras.estimator.model_to_estimator(keras_model_path='iris-20200719.h5', model_dir='./')
feature_spec = {'dense_1_input': model.input}
serving_input_fn = export.build_raw_serving_input_receiver_fn(feature_spec)
estimator._model_dir = './keras'
estimator.export_savedmodel('iris-20200719', serving_input_fn)
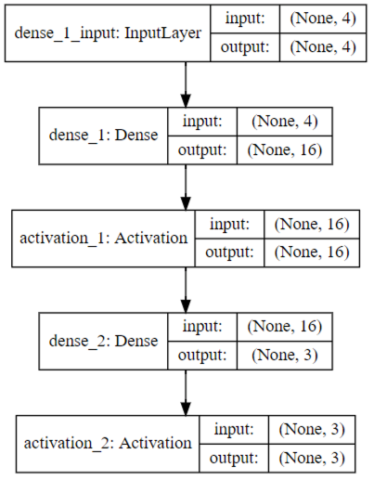
ここで、feature_specは、モデルで推論を行う際の入力値の形式を指定します。dense_1_inputというのは、モデルの最初がDense(通常のフルコネクトなニューラルネットワーク層)で、その1つ目のインプットだから…ということなのですが、モデルを可視化してみると分かります。最初の層にdense_1_inputという名前が付いていますね。
DockerでTensorFlow Servingを動作させる
tensroflow/servingというコンテナが公式で提供されているので、そのまま使います。
パラメータの意味を少し説明しておくと、-p 8500:8500はポートの指定です。後のところで--port=8500のようにTensorFlow Servingが8500番ポートで待ち受けするようにしていますので、それをホスト側でも8500番で使えるようにしています。--mountは、ホスト側でのSavedModel形式のファイルのパスを、ゲスト(コンテナ)側にマウントしています。今回はホストがWindowsなのでD:/dev/iris-20200719のようになります。--entry-point=tensorflow_model_serverは、TensorFlow Servingの実行パスの指定です。--model_name=irisは後でモデルを呼び出して推論を行う際に指定する名前となります。--model_base_path=/models/irisはTensorFlow Servingで動作させるSavedModel形式のファイルのパスであり、先ほど/models/irisというパスにマウントしたので、それを指定します。
docker run -p 8500:8500 --mount type=bind,source=D:/dev/iris-20200719,target=/models/iris -t --entrypoint=tensorflow_model_server tensorflow/serving --port=8500 --model_name=iris --model_base_path=/models/iris
正常に動作すると、このようなメッセージが表示されます。

推論の実行
最後に、TensorFlow Servingで動作させるモデルを呼び出し、推論を実行します。
PythonからTensorFlow Servingを呼び出すにはAPIのインストールが必要です。今回は、TensorFlow 1.15を導入している環境にインストールするので、バージョンを指定しています。
pip install tensorflow-serving-api==1.15
あとは、Notebook上で下記のようなプログラムを実行します。
import grpc
import tensorflow as tf
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2_grpc
channel = grpc.insecure_channel('localhost:8500')
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
request = predict_pb2.PredictRequest()
request.model_spec.name = 'iris'
feature = [[float(-0.05250608), float(-0.59237301), float(0.76275827), float(1.58046376)]]
request.inputs['dense_1_input'].CopyFrom(tf.contrib.util.make_tensor_proto(feature))
result = stub.Predict(request, 10.0)
print(result)
実行結果は下記のように表示されます。

3つのfloat_valが出力されますが、これはIrisデータセットが3つのラベルのいずれかに分類するためのものだからです。3つ目の値が最大なので、その品種に分類されたことになります。(ちなみに、この分類は正解です。)