
M1 Macで何かやるという記事を何本か書いてきましたが、次は物体検出のYOLOv3を動かしてます。
こちらの記事を参考にさせていただきました。ありがとうございます。

仮想環境を作る
Python環境はあらかじめ、asdfでminiforge3-4.10.3-10をインストール済みです。
condaで仮想環境を作るところから始めます。今回は、Python 3.9を使用しました。
conda create -n yolo python=3.9
conda activate yolo
必要なライブラリのインストール
conda install numpy matplotlib pandas opencv
PyTorchのインストール
PyTorchはM1 Macに対応したものを、こちらからダウンロードします。
画面の真ん中くらいの右にあるDownloadボタンをクリックすればOKです。
ダウンロードしたら、インストールします。
pip install torch-1.8.0a0-cp39-cp39-macosx_11_0_arm64.whl
PyTorch YOLOv3のダウンロード
GitHubからクローンします。
git clone https://github.com/ayooshkathuria/pytorch-yolo-v3.git
cd pytorch-yolo-v3
YOLOv3のダウンロード
YOLOv3の学習済みモデルをダウンロードします。
wget https://pjreddie.com/media/files/yolov3.weights
静止画の物体検出を試す
あとは、下記のコマンドを実行すれば物体検出できます。
python detect.py --images imgs/dog.jpg --det det
と、いう話なのですが、私の環境(or 今回入手したバージョン?)ではエラーになってしまいました。
(yolo) inoccu@honey pytorch-yolo-v3 % python detect.py --images imgs/dog.jpg --det det
Loading network.....
Network successfully loaded
dog.jpg predicted in 0.217 seconds
Objects Detected: bicycle truck dog
----------------------------------------------------------
Traceback (most recent call last):
File "/Users/inoccu/Dropbox/dev/pytorch-yolo-v3/detect.py", line 300, in <module>
list(map(lambda x: write(x, im_batches, orig_ims), output))
File "/Users/inoccu/Dropbox/dev/pytorch-yolo-v3/detect.py", line 300, in <lambda>
list(map(lambda x: write(x, im_batches, orig_ims), output))
File "/Users/inoccu/Dropbox/dev/pytorch-yolo-v3/detect.py", line 292, in write
cv2.rectangle(img, c1, c2,color, 1)
cv2.error: OpenCV(4.6.0) :-1: error: (-5:Bad argument) in function 'rectangle'
> Overload resolution failed:
> - Can't parse 'pt1'. Sequence item with index 0 has a wrong type
> - Can't parse 'pt1'. Sequence item with index 0 has a wrong type
> - Can't parse 'rec'. Expected sequence length 4, got 2
> - Can't parse 'rec'. Expected sequence length 4, got 2
Object Detectedの表示はちゃんと出ているので、YOLOでの物体検出は上手く行ったのだと思いますが、最後の境界線を描いた画像を出力するところでエラーになっているようです。
こちらのやり取りを参考にして、detect.pyの285行目から始まるwrite関数の一部を修正しました。
def write(x, batches, results):
#c1 = tuple(x[1:3].int())
c1 = tuple(x[1:3].cpu().int().numpy())
#c2 = tuple(x[3:5].int())
c2 = tuple(x[3:5].cpu().int().numpy())
修正後に、再度、物体検出を試すと、このようなメッセージが表示されました。
(yolo) inoccu@honey pytorch-yolo-v3 % python detect.py --images imgs/dog.jpg --det det
Loading network.....
Network successfully loaded
dog.jpg predicted in 0.190 seconds
Objects Detected: bicycle truck dog
----------------------------------------------------------
SUMMARY
----------------------------------------------------------
Task : Time Taken (in seconds)
Reading addresses : 0.000
Loading batch : 0.283
Detection (1 images) : 0.190
Output Processing : 0.000
Drawing Boxes : 0.021
Average time_per_img : 0.495
----------------------------------------------------------
det/det_dog.jpgという画像が生成されているので、表示してみると、このような画像が出力されていました。

完璧ですね!
カメラでのリアルタイム物体検出も試す
カメラの方も、同様のコード修正が必要です。cam_demo.pyの43行目あたりです。
def write(x, batches, results):
#c1 = tuple(x[1:3].int())
c1 = tuple(x[1:3].cpu().int().numpy())
#c2 = tuple(x[3:5].int())
c2 = tuple(x[3:5].cpu().int().numpy())
下記のコマンドで起動します。
python cam_demo.py
こんな感じの画面が開いてカメラで撮影した映像が表示されます。合わせて、物体検出されてPersonとか出てますね。上手く動いているようです。
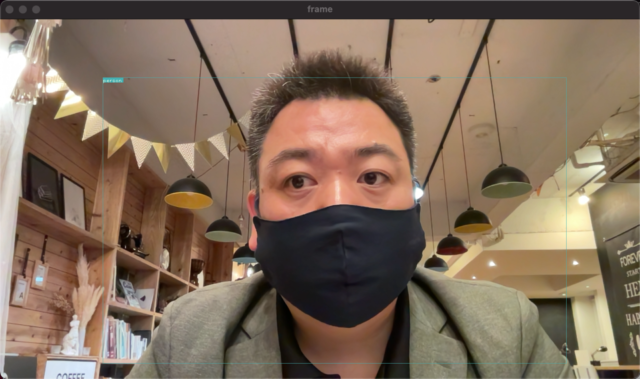
私の画像で恐縮です。
ちなみに、今日はCode for KitakyushuのAIもくもく会に来ています。背景は会場の秘密基地というコワーキングスペースです。