IBMでAIとか機械学習系のことというとWatsonが思い浮かぶわけですが、いわゆるBluemixで使えるWatson APIは文章や画像といった非構造化データのコグニティブ(認識)系サービスだけを提供していて、数値などの構造化データのソリューションは提供していません。
IBMのクラウドサービスを広く見ると、Bluemixの中にもdashDBのようなデータウェアハウスがありますし、Watson AnalyticsといったSaaSが構造化データの分析に相当します。では、もう少しエンジニアライクというかプログラミングライクな環境はというと、最近登場したIBM Data Science Experienceを挙げることができます。
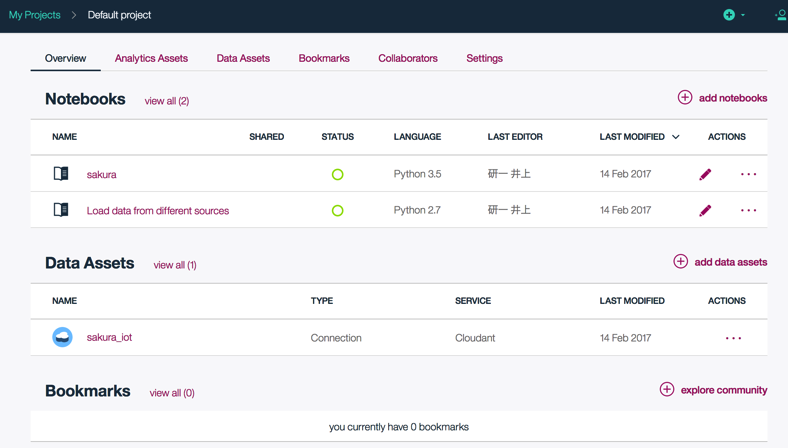
いままで、Arduinoにセンサーを付けでデータを取得し、さくらのIoT Platformを使ってクラウドにアップし、それをBluemix内のNoSQLデータベースであるCloudantに蓄積するという流れをひととおり作ることができました。

ここで蓄積したデータを、IBM Data Science Experienceで何かやろうというのが今回の記事です。
IBM Data Science Experienceとは
IBM Data Science Experienceはデータサイエンスに関する様々なツールをまとめて提供するクラウドサービスという説明で良いのか・・・は分かりませんが(たぶん間違ってはないと思う)、私的に言えば、CloudantやdashDBといったBluemix上のデータベースからデータを取得し、使い慣れたJupyter Notebooksでなんだかんだできるというのが嬉しい。
データソースは他にもローカルファイルをアップロードしたり、Amazon S3からインポートしたりといったこともできます。またJupyterだけでなくRStudioも使えるらしいので、Python派だけでなくR言語派も嬉しいということのようです。(R言語ならdashDBでも使えますが・・・。)
また、Notebookの内容を共有したり、GitHubやGistと連携するといった、コラボレーションを促進する作りになっているのもイケてる感があります。
あと、機械学習環境もComing soonということになっています。

気になる価格体系ですが、Bluemixの例によって30日間は無料のようです。
その後は、Jupyter Notebooksを使う場合に必要なApache Spark環境が$0.70/インスタンス時間ということのようです。また、データストレージは5GBまで無料。Bluemix上のCloudantなど別のデータベースを使用する場合は、そちらの料金がかかるだけということではないでしょうか。
(ただ、ここで使用するApache Spark環境もBluemixの1サービスであり、BluemixのカタログでApache Sparkの料金プランを見てみると、Personal-Freeプランは無料となっているので、ずっと無料かもしれません。)
※料金体系の詳細はIBM Data Science Experienceのサイトをご自身でご確認ください。上記の記述は誤っているかもしれませんが、その場合の責任は負いません。
Data Science Experienceの構造
Data Science Experienceにログインしてみると、Community、My Project、RStudio、ObjectStorageの4つメニューがあります。
Communityでは解説記事やチュートリアルのほか、シェアされたデータセットやノートブックを参照することができます。IBMがAuthorになっているものも多いので、Data Science Experienceの使い方などで迷ったらCommunityから検索してみるのが良いかもしれません。
My Projectはこのサービスの中心です。作業を始めるときはプロジェクトを作成し、そこにノートブックやデータセットなどを登録していきます。また、共同作業するメンバーの追加や、Gitリポジトリ(GitHubなど)の登録もプロジェクト単位で行います。
RStudioはその名のとおり、R言語の環境です。
ObjectStorageはプロジェクト間で共有できるデータの保存場所です。プロジェクトのデータソースとして使用することができるのだと思います。
プロジェクトでJupyter Notebookを始める
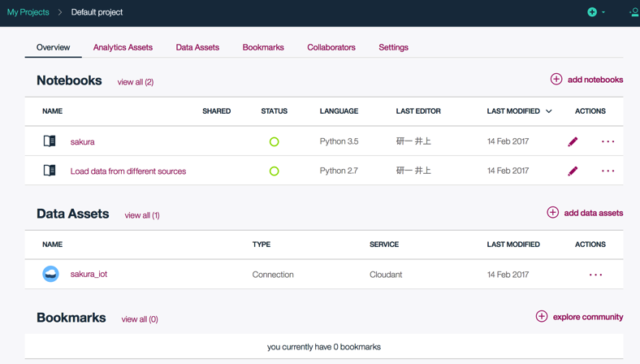
既にいくつかのノートブックが追加されていますが、これがプロジェクトの画面です。
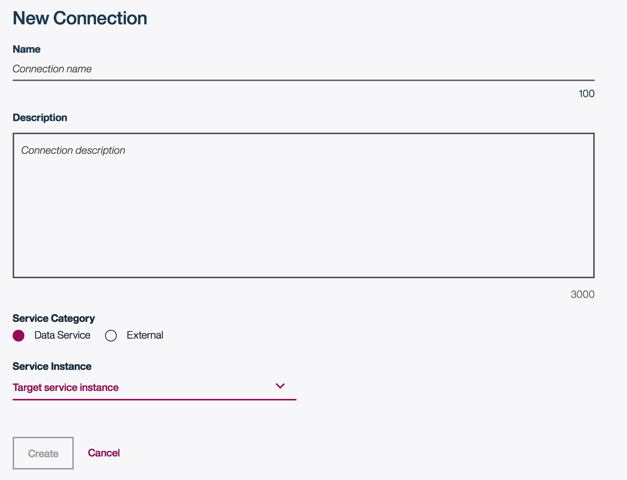
ノートブックを追加する前に、データソース(データアセット)を追加しておくと良いでしょう。add data assetsボタンをクリックするとConnect画面が開くので、Connectを追加します。Bluemix上にCloudantやdashDB環境がある場合はそこから選択できるほか、Externalを選択すると、S3、RedShiftといったAWSサービス、Azure、MySQL、PostgreSQL、Oracleなどだいたいのサービス及びソフトウェアと接続することができるようです。
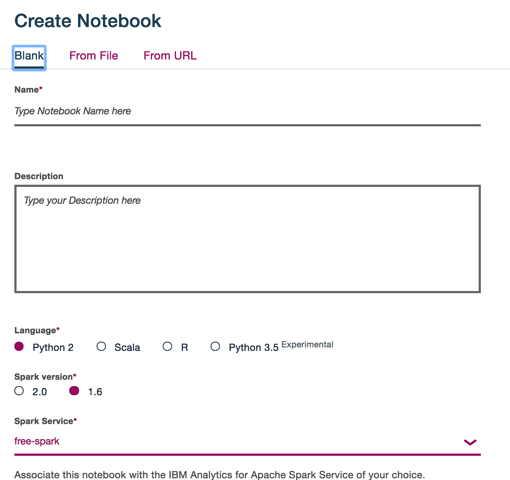
次に、add notebookボタンをクリックしてノートブックを追加します。言語はPython2か3.5、Scala、Rから選択できます。(Python3.5は実験的な提供です。)
ノートブックはApache Spark環境で動作するので、使用するSparkサービスを選択します。(1つも作成していない場合は、この画面から作成できます。ここで追加したApache Spark環境もBluemixの1サービスという位置づけになります。)
Jupyter Notebooksで作業する
ノートブックを作ってしまえば、あとはいつもどおりに作業するだけです。
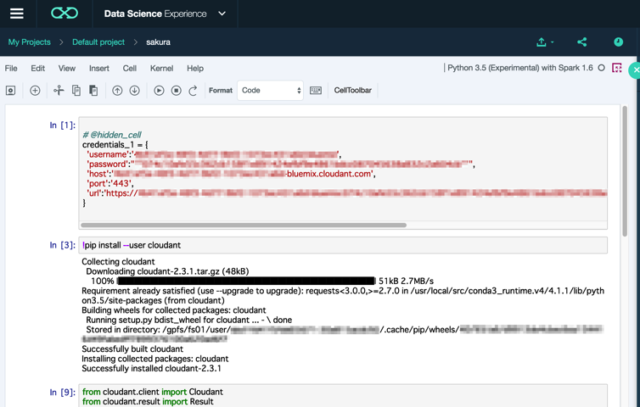
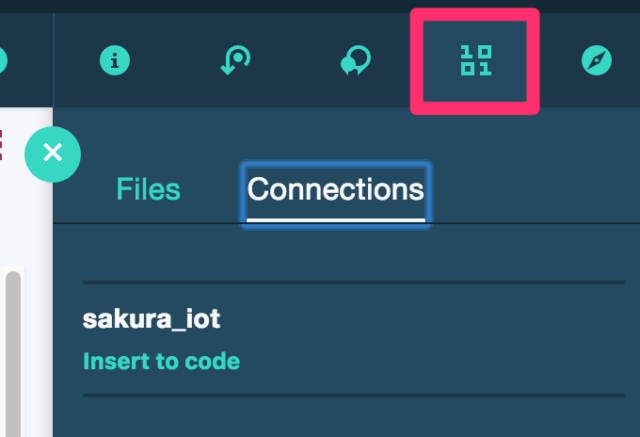
ノートブックの右上部分のアイコンをクリックすると、Connections画面が開きます。Insert to codeリンクをクリックすると、接続に使用するクレデンシャルセルが追加されます。あとは、ふつうにPythonコードを書いてデータ取得する必要があります。
Cloudantに接続するには、まずcloudantパッケージをインストールします。
!pip install --user cloudant
Cloudantに接続して、データベースの一覧を取得するコードです。
from cloudant.client import Cloudant
from cloudant.result import Result
client = Cloudant(credentials_1["username"], credentials_1["password"], url=credentials_1["url"])
client.connect()
client.all_dbs()
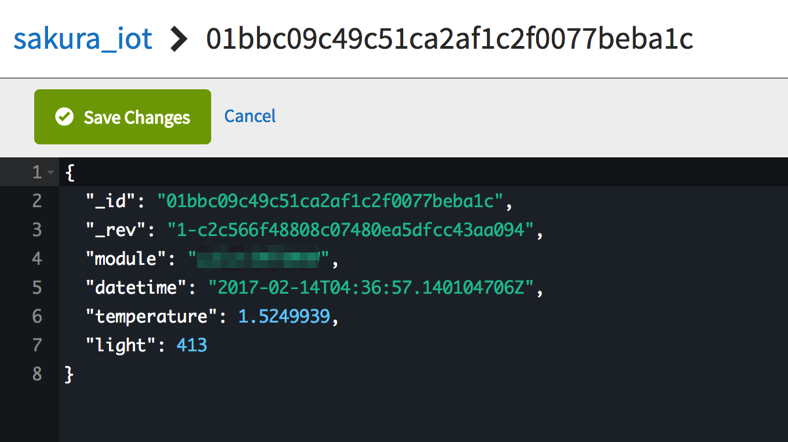
Arduinoから、さくらのIoT Platform経由でCloudantに蓄積したデータを可視化してみます。
ご参考までに、残りのコードです。
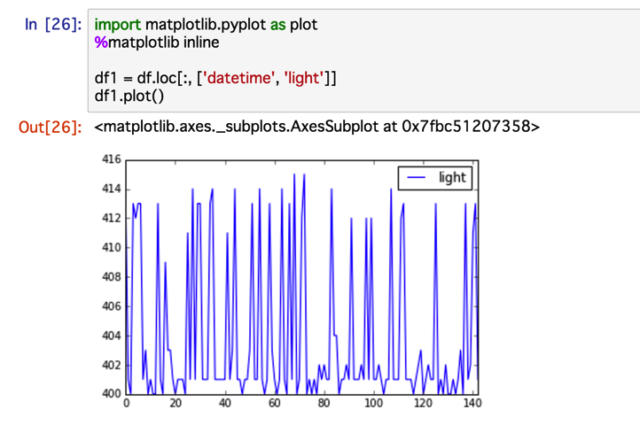
df.head()でデータフレームの先頭5行くらいを表示した後で、グラフ(照明センサーの時系列グラフ)で使用する列のみに絞り、df1.plot()でグラフを表示します。
import pandas as pd, json
db = client['sakura_iot']
result_collection = Result(db.all_docs, include_docs=True)
df = pd.DataFrame([item['doc'] for item in result_collection])
df.head()
import matplotlib.pyplot as plot
%matplotlib inline
df1 = df.loc[:, ['datetime', 'light']]
df1.plot()
このようにmatplotlibを使った可視化ができました。
(追記)
このグラフ、よく見てみると時系列に並んでいません。そこで、このようなコードにする必要があります。
import pandas as pd, json
db = client['sakura_iot']
result_collection = Result(db.all_docs, include_docs=True)
df = pd.DataFrame([item['doc'] for item in result_collection])
df = df.set_index('datetime')
df.index = pd.to_datetime(df.index, utc=True).tz_convert('Asia/Tokyo')
df.index = df.index.tz_localize(None)
df = df.sort_index()
df.head()
import matplotlib.pyplot as plot
%matplotlib inline
df1 = df.loc[:, ['light']]
df1.plot()