
ほとんど出落ちというか、タイトルがこの記事で言いたいことのすべてなのですが・・・。
Watsonの画像認識サービスであるVisual Recognitionを使って、ある企業の新サービスを作れるかどうか検証するというお仕事をしています。
最初はかなり少なめの枚数を学習させてみると、認識精度は「当たるも八卦当たらぬも八卦」よりはマシというか、ちゃんと認識出来るものと、なかなか難しいものがきれいに分かれるような結果となりました。
認識精度を上げるための方法は、ドキュメントにまとまっていて、こちらのようなガイドラインがあります。例えば、1つのクラスあたり50枚以上の訓練データを準備するとか、ネガティブデータもあった方が良いとか、そういうものです。
そこで、もともと作ってあるカスタムモデルの精度を向上させるため、訓練データを増やすという方法をまず試すことにしました。
以前のVisual Recognitionは、既存のカスタムモデルに訓練データを増やすということはできず、常に常に新規のカスタムモデルを作る必要がありました。自然言語を分類するNatural Language Classifier(NLC)は、いまでもそうですね・・・。
しかし、最近のAPIリファレンスを見ると、update_classifierというAPIがあって、既存のカスタムモデルに訓練データを追加することができるようになっています。Watson SDKでもきちんと対応しています。最近の私は、CurlよりもPythonのSDKでAPIを叩くことが多いので、SDKのソースとサンプルコードだけ見て、APIリファレンスはあまり読まない・・・という感じが増えています。
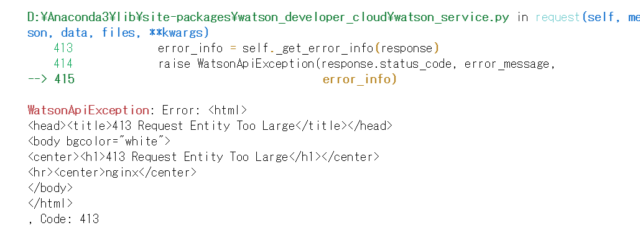
で、update_classifierをやってみたところ、何回やっても、こういうレスポンスが返ってくるのです。
WatsonApiException: Error:
<center></center>
<h1>413 Request Entity Too Large</h1>
<hr />
<center>nginx</center>
, Code: 413
HTMLがそのまま来るというのも凄いですが、それはさておき、Request Entity Too Largeらしい。
クラス数が多いので、試しに1つのクラスの訓練データを送ってみても、結果は同じ。だいたい、もっと大きなサイズのデータを使って、初回のcreate_classifierをやっているので、どうにも解せない。
で、あらためてAPIリファレンスを読むと、こんなことが書いてありました。
Important: You can’t update a custom classifier with an API key for a Lite plan. To update a custom classifer on a Lite plan, create another service instance on a Standard plan and re-create your custom classifier.
なるほど。ライトプランだと、そもそもupdate_classifierはできない・・・。しかも、ちゃんとImportantって言ってる。
ということで、やっぱりリファレンスはきちんと読まないといけないなと、感じた次第。
お仕事だし、ライトプランじゃなくて、標準プランに切り替えるか・・・。’